Building ASTRA: What a Telegram Stars Exchange Taught Me About Scale
It Started With a Simple Idea
A friend of mine came to me with an idea: build a system where people can sell Telegram Stars and get paid instantly. We talked it through and my first reaction was honest: this looks easy. The flow is straightforward. A buyer opens a Telegram invoice, pays in Stars, the payment gets confirmed, and the system sends money to the seller. Four steps. Maybe a weekend project.
I was wrong. Not about the flow itself, that part is actually simple. But the moment you put real money and real users into the equation, everything you thought you knew gets tested. This project pushed me into corners of the TON blockchain I had only read about in documentation, and forced me to confront infrastructure problems I had been ignoring for too long.
This is the story of building ASTRA, and everything I learned along the way.
The First Version
I had worked with TON before, but never on something where actual money was moving between real people. That changes your mindset completely. Every edge case stops being theoretical. Every timeout becomes a potential support ticket from an angry user who thinks their money just vanished.
The stack was simple. A Telegram bot for the user-facing side, a FastAPI backend handling the business logic, and a PostgreSQL database for persistence. For payments, I used the TON SDK and connected it to a standard TON wallet. The logic was clean: when a purchase gets confirmed, the backend triggers a transfer from the platform wallet to the seller.
It worked. For the first handful of users, everything was smooth. Transactions went through, sellers got paid, nobody complained. I thought I was done.
The Wall
Then usage started growing. And I started noticing something that made my stomach drop.
A standard TON wallet uses something called a seqno, a sequential counter. Every outgoing transaction must include the next number in the sequence. Transaction number 42 cannot go out until transaction 41 is confirmed on-chain. This means the wallet processes one transaction at a time, in strict order.
Now imagine it is peak hours and thirty sellers are waiting for their payouts simultaneously. The system would queue them up, process one, wait for on-chain confirmation, then move to the next. Some users waited minutes. For a platform that promises instant payouts, minutes feel like hours.
I knew I needed something different.
Discovering Highload Wallets
I started digging through TON documentation, reading through GitHub repos, searching for how exchanges and payment processors handle high-throughput on this chain. That is when I found it: the Highload Wallet v3.

The concept clicked immediately. Instead of using a sequential counter, the Highload Wallet uses a query_id system. Each transaction gets a unique identifier, and the contract can accept multiple external messages in parallel without waiting for previous ones to confirm. No more queue. No more sequential bottleneck.
But the part that really got me excited was the batching capability. A single internal transfer on a Highload Wallet can carry up to 254 messages. Think about what that means. If a thousand users want to sell Stars at the same time and your infrastructure can handle the load, you can batch those payouts into just four transactions instead of a thousand sequential ones.
You simply cannot do that with a standard wallet. It is not a matter of optimization or clever coding. The architecture of a normal wallet does not allow it. The seqno design makes it physically impossible to send more than one transaction at a time.
Learning and integrating the Highload Wallet was one of the most rewarding technical experiences I have had. It took me from reading documentation to understanding how smart contract design decisions at the protocol level directly impact what you can build on top of them.
The Latency Problem
With the wallet bottleneck solved, I expected the system to feel fast. It did not.
Users were still complaining about slow responses. The bot would take a noticeable beat before replying, and in a trading context where people are watching their money move, even a half-second delay feels wrong. It erodes trust.
I started profiling. The backend logic was fast. The TON interactions were fast. So where was the time going?
The database.
I was running the application on my own server but using Supabase for the database. Managed PostgreSQL, hosted in the cloud. I had been careful to pick the same region for both my server and the Supabase instance, thinking that would be enough. It was not.
Every single database query, and there are many per transaction, had to make a network roundtrip to Supabase and back. Even with the same region selected, that is still a hop through the public internet, through load balancers, through connection pooling layers. Each query added a few milliseconds, but those milliseconds stacked up fast when a single user action triggers five or six database reads and writes.
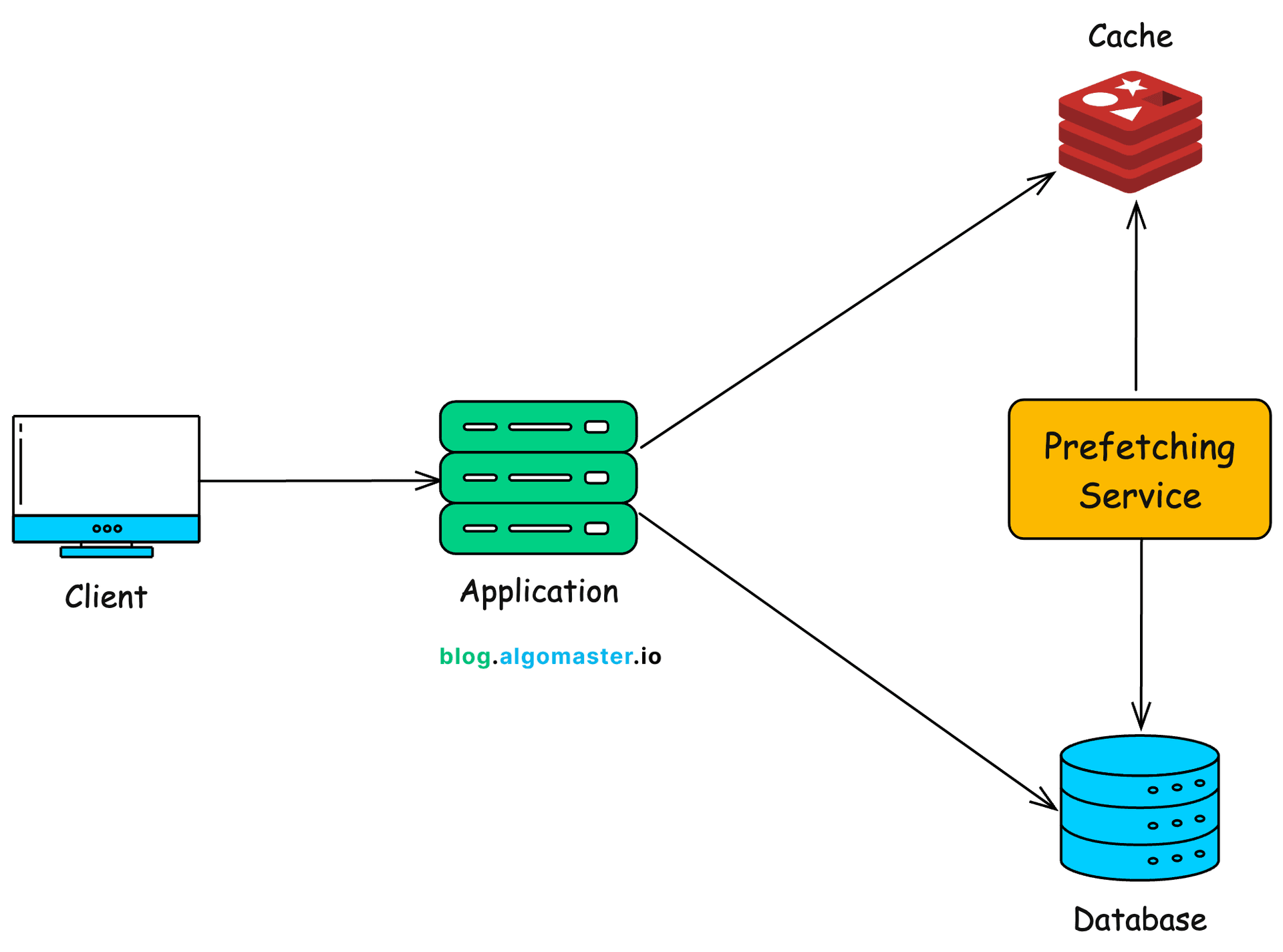
The fix had two parts. First, I moved the database to the same server the application was running on. Local PostgreSQL, no network hop, just a Unix socket connection. The difference was immediately felt. Queries that took 15-30ms over the network now completed in under a millisecond.
Second, I introduced a caching layer for frequently accessed data. User profiles, active listings, rate information, anything that gets read way more often than it gets written. This cut the database load even further and made the bot responses feel instant.
I want to be clear about something: caching alone would have helped, and moving the database alone would have helped. But neither one by itself would have delivered the experience I wanted. The combination is what made it work. The local database eliminated the baseline latency, and the cache eliminated redundant queries on top of that.
This was one of those lessons you read about in every systems design book but never truly internalize until you feel it in production. Latency is not just a number in a benchmark. It is the difference between a user who trusts your platform and a user who moves to a competitor.
The Numbers
After all the iterations, the rewrites, the late nights debugging transaction edge cases, ASTRA reached a point we are genuinely proud of.
Here is a snapshot from one of the earlier periods showing the bot's revenue chart and Stars balance. You can see the spikes during peak activity when the system handled bursts of concurrent transactions without breaking.
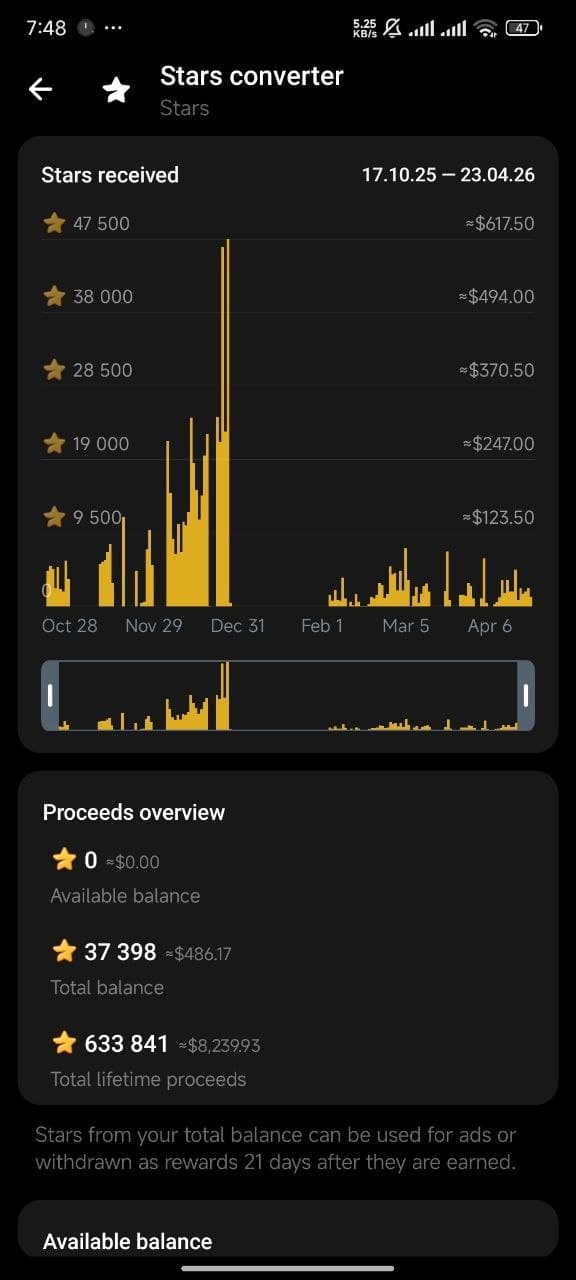
The platform has since grown well past those numbers. Hundreds of transactions completed successfully, all recorded and verifiable on the TON blockchain. Real money moving between real people, every single transfer traceable on-chain.
These are not massive numbers by exchange standards. But for a project that started as a "simple" Telegram bot, they represent something meaningful. Real money, real users, real trust.
What I Actually Learned
If I had to compress the entire experience into a few takeaways, these are the ones that stuck with me.
Building on a blockchain for real users is fundamentally different from building hobby projects. When someone's money is on the line, your error handling needs to be perfect, your logging needs to be exhaustive, and your transaction verification needs to be paranoid. I implemented idempotency checks, on-chain state verification, and detailed audit logs not because a tutorial told me to, but because the first time a user messaged me saying "where is my money?" I realized how critical those things are.
Infrastructure choices that seem minor on day one become defining constraints at scale. The decision to use a remote database, the choice of a standard wallet, even the way I structured my async handlers, all of these small choices compounded into real problems that took significant effort to fix.
And finally, sometimes the most impactful technical improvement is not a clever algorithm or a new framework. Sometimes it is just moving your database to the same machine as your application. The boring solution is often the right one.